Last time I bolted OpenTelemetry onto my espresso machine and called it a tiny industrial process worth instrumenting. The signals were good. Gauges for the boiler and pump, a span per shot, exemplars linking metrics back to traces. What I didn’t have was two things that turned out to matter more than any of the clever bits. Dosage and grind size changes, so I needed a way of making that dynamic.
As nice as it is to have all of these pretty graphs showing me things, I really did need a way to easily understand what I can improve. I know what channeling looks like when I pull a shot, but I still figured that it’d be fun to just add one more thing.
So this is the follow-up, in four parts: the grind-and-dose UX that make it easy to see what the settings are at a glance as well as set them, a custom OpenTelemetry Collector running in Home Assistant that funnels both the Gaggia and the rest of my house into ClickHouse, an export-path rework that makes the shot data fine-grained enough to trust, and an agent sitting on top of ClickHouse that reads it all back and tells me what I did wrong.
Part one: the machine now knows what a grinder is
I figured I’d add coffee.grind.level, coffee.dose.weight_g and coffee.brew.ratio. Brew ratio is obviously a pretty important metric to look at when brewing coffee. Because I have a shitty analog grinder, though, there’s no way to feed the grind size or dose weight into the machine. You’d dial the grinder on the grinder, scoop a dose onto a scale, and the machine knew none of it. The most important inputs to a shot were the two it couldn’t see.
Now the firmware ships a grinder catalogue. You pick your grinder once in settings and the machine learns its scale:
Custom / Generic 0–100, step 1Varia VS3 0–20, step 0.1 (stepless dial)Niche Zero 0–50, step 1Baratza Encore / Encore ESP 1–40, step 1Fellow Ode Gen 2 1–11, step 11Zpresso (J/JX/K) 0–100, step 1 clicksComandante C40 0–50, step 1 clicks…and a few moreEach entry is just a min, a max, a step, and an optional unit suffix. That’s the whole abstraction. The brew screen grows a grind/dose pane: two pairs of plus/minus buttons, one for grind level, one for dose. Grind nudges by the grinder’s own step (so a Varia moves in 0.1, an Encore in whole numbers) and snaps to that step relative to its minimum, clamped to the dial’s range. Dose moves in 0.5g and clamps to a sane 0.1–60g. Below them sits a live brew ratio, 1:2.0 and friends, computed from the target yield over the dose.
The same controls exist in the Web UI, because squinting at a 2.4-inch screen is genuinely not a good time. There’s one source of truth, though. The grinder table lives in the firmware (Grinders.h) and is mirrored byte-for-byte in the Web UI (grinders.js), same order so the index is the id. Pick “Niche Zero” in the browser, the firmware agrees on what “Niche Zero” means.
The buttons aren’t the point. The numbers I was already exporting are now real, set-on-the-device values instead of guesses. The grinder model rides along as a resource attribute (coffee.grinder.model), the grind level and dose land on every shot span, and while a shot pulls, the live gauges get tagged with the current grind level, phase, and a coffee.shot.id that is the shot’s trace id. That last one is the join key: every boiler-temperature and pump-flow sample taken mid-shot carries the same id as the span it belongs to, so a gauge reading and the shot trace are one WHERE coffee.shot.id = … apart. “Too sour” finally has a grind setting attached to it, and “ran too much water through too little coffee” is now a ratio I can sort by. Given the relatively low volume of data and the fact that I was feeding this into an OLAP database, cardinality wasn’t a concern.
Part two: where all the data actually goes
The original post hand-waved the backend with “point it at whatever OTLP collector you like.” Fine for a demo. In practice I wanted the espresso data to live next to the rest of the house, the temperature sensors and the energy meter and the zigbee swarm, so I could ask questions that span both. The kitchen being cold and the shot running long are not unrelated events, and I’d like to prove it.
That backend is its own project now: ha-otelcol, a Home Assistant add-on that runs a custom-built OpenTelemetry Collector. Custom-built, because the upstream collector-contrib distribution does not ship an MQTT receiver and no maintained third-party one exists. Home Assistant speaks MQTT for half of everything, so a collector that can’t read MQTT is a collector that can’t see my house.
Building a collector that didn’t exist
The fix is the OpenTelemetry Collector Builder. You hand OCB a manifest of the components you want and it compiles a bespoke collector binary. Mine pulls the usual OTLP receivers, the batch and memory-limiter processors, the ClickHouse / OTLP / file / debug exporters, and one component that isn’t on the menu: a small in-repo Go MQTT receiver.
receivers: - gomod: go.opentelemetry.io/collector/receiver/otlpreceiver - gomod: github.com/local/mqttreceiver v0.0.0 # in-repo, replaced locallyexporters: - gomod: .../exporter/clickhouseexporter - gomod: go.opentelemetry.io/collector/exporter/otlpexporterThe MQTT receiver is the interesting bit. It subscribes to the broker and turns messages into OTel signals on the fly. As metrics, a JSON object becomes one gauge per numeric field (nested objects flattened with dotted names, non-numbers skipped), a bare number becomes a single gauge named after the topic, and a boolean becomes a 1/0. As logs, each message becomes one record with mqtt.topic, mqtt.qos, mqtt.retained and mqtt.message_id attributes. The factory implements both CreateMetrics and CreateLogs, so the same receiver can sit in a metrics pipeline and a logs pipeline at once if you want your zigbee chatter as both numbers and audit trail.
The whole thing builds in CI and publishes prebuilt multi-arch images to GHCR, so installing the add-on is a quick download rather than a twenty-minute on-device Go build. Same principle as the firmware’s OTA story: the user shouldn’t have to compile anything to get a working thing. I’ve also got it working pretty seamlessly as a Home Assistant add-on, so you can easily consume any updates that I make.
I did have an AppArmor profile configured, but I need to spend a bit more time poking holes in it in it to get it working properly.
Two streams, one database
The pipeline is deliberately boring. Two sources feed in:
- the Gaggia, over OTLP/HTTP, exactly as the last post described;
- Home Assistant’s MQTT broker, every sensor that publishes to it.
Both run through a batch processor and a memory limiter (this is a Raspberry Pi, not a datacentre) and land in the same place:
exporters: - type: clickhouse endpoint: "clickhouse:9000" database: otel ttl: 720hClickHouse, because it’s a columnar database that eats high-cardinality time-series for breakfast and lets me ask questions in SQL instead of a proprietary query language I’ll forget by next week. The collector’s ClickHouse exporter creates its own schema, one set of tables for metrics, one for logs, one for traces, and just writes to it.
The high-cardinality part is what makes coffee.shot.id safe to attach in the first place. On a traditional TSDB, every distinct attribute value forks a new time series, so stamping a unique id onto a metric is the classic way to blow up your active series count and your bill. ClickHouse doesn’t play that game: attributes are just columns in a Map, a new shot id is a few more rows and not a new series, and the engine is built to filter and group over exactly that kind of wide, high-cardinality data. The id is one more value in a wide event, and the wide event is what OLAP was made for.
The result is the thing I actually wanted. My espresso shots and my house live in the same database, queryable in one join. I can line up a shot’s temp.stability_c against the kitchen ambient temperature MQTT was reporting at 7am. I can check whether the grinder’s circuit drew its usual spike right before a shot, or whether the board’s WiFi disconnects correlate with the microwave. None of these are questions a coffee app would ever let me ask, because a coffee app would never have my house’s data sitting in the next table over. Here both are just rows with a timestamp, which is the entire point.
Part three: ten seconds is a long time in a shot
Metrics exported on a fixed interval, ten seconds by default, and each tick shipped exactly one reading per gauge, whatever the latest value happened to be at that instant. For the boiler temperature idling around a setpoint, fine. For the scale weight during a shot, useless.
A shot runs twenty-five to forty seconds and the weight ramps the whole way; three or four samples don’t describe that curve, they caricature it. I was sorting shots by final_weight_g and I wasn’t getting a full picture of what was happening.
The honest fix is to stop conflating two different things. How often I sample a signal and how often I ship it have nothing to do with each other. So the export task now reads the live gauges every 500ms into a small ring buffer and flushes the whole batch every ten seconds. OTLP gauges happily carry many data points, each with its own timestamp, so one POST now holds twenty timestamped weight readings instead of one. Same single HTTPS round trip, twenty times the resolution. That round-trip count matters more than it sounds. TLS handshakes on an ESP32 are not free, and the entire reason to batch rather than just lower the interval is to avoid unecessarily noisy handshakes on a resource constrained device.
Then nanopb happened.
#error Enable PB_FIELD_32BIT to support messages exceeding 64kB in size: otlp_ScopeMetrics, otlp_ResourceMetrics, otlp_ExportMetricsServiceRequestnanopb trades flexibility for determinism. Every message is a statically-sized C struct. Exactly what you want on a microcontroller, right up until you ask for twenty data points across fourteen metrics and the struct shits itself. Field offsets inside a message are encoded in sixteen bits, so a single message can’t exceed 64KB, and mine now wanted around 115KB. There’s a global flag, PB_FIELD_32BIT, that lifts the ceiling for the whole build. I didn’t want it.
A way to optimise this is to keep the struct small (eight points per gauge) and emit the twenty-point batch as several ResourceMetrics messages concatenated into one request body. This works because of a quiet property of protobuf: concatenating two serialised messages of the same type is a valid serialised message, with repeated fields appended. So three small encodes back-to-back in the buffer decode, at the collector, as one request with three ResourceMetrics. The cumulative counters are written once, in the first chunk, so nothing double-counts. One POST, the struct stays at ~47KB, everyone’s happy.
The part I cared about most is that none of this can brick the machine mid-shot. The encoder writes into a fixed buffer, and nanopb’s pb_ostream_from_buffer refuses to write past the end: the encode fails closed and drops that export rather than scribbling over memory. To prove that instead of asserting it, the encoder now compiles and runs on my laptop, so a host test builds the real thing against tiny shims, feeds it the worst case (every gauge full of in-shot points, attributes and exemplars and all), and checks two things: the worst-case batch is 30,339 of 40,960 buffer bytes, 74%, comfortably inside; and across every buffer size from zero upward, with a canary planted past the end, the encoder never once writes out of bounds. A compile-time static_assert guards the 64KB wall so the next time I add a metric I get a readable error instead of the one above.
And the payoff lands right back in ClickHouse. Finer samples are just more rows: the one thing the entire back half of this post is built not to care about. The weight curve is finally a curve.
Part four: a critic that reads the database
Three sections of plumbing and the data just sits there. ClickHouse will answer any question I can phrase in SQL, but at 7am I don’t want to write a windowed aggregate over my own espresso. I want something to look at the last shot and tell me what I did wrong.
ClickHouse Cloud ships a hosted LibreChat wired to the database over the ClickHouse MCP server. An agent there gets read-only MCP tools, list_tables and run_select_query, and I point them at the same otel database the collector writes to. No new pipeline and no export job; the analysis layer reads the same rows everything else does.
So I built a critic. It’s called Hoff Jamesman, an homage to a certain YouTube coffee authority, and its whole job is to pull my shot traces and metrics out of ClickHouse and tell me, in the dry voice of a man who has tasted more espresso than is wise, how I ruined breakfast.
The role prompt is short: you are a coffee analyst for a GaggiMate, you query ClickHouse read-only over MCP, you turn what you find into a verdict the user can act on. The prompt is the easy part. The skill behind it is where the work is.
The skill is the methodology
A role prompt makes the agent talk like a coffee analyst. It doesn’t make it a good one. Left alone it’ll SELECT *, glance at a final weight, and announce the shot was “a bit fast”, which is the espresso equivalent of staring at an average and calling it a day.
The skill is where the actual method lives: which tables hold the shot spans and which hold the mid-shot gauges, how to join them on coffee.shot.id, what a channelled puck looks like in puck.resistance_cv, what counts as a healthy boiler swing, and how to turn all of that into a score. It’s long, because doing this properly is a lot of “if the CV is above this and the yield is below that, say that.” Folded away so it isn’t the whole page:
Skill: shot-analysis — the agent’s analysis methodology
# Coffee Snob
You analyse espresso telemetry from a GaggiMate (an ESP32 bolted onto a Gaggia) thatexports OpenTelemetry to ClickHouse. The same ClickHouse also holds the rest of the user'shouse (Home Assistant over MQTT). You query it read-only through the ClickHouse MCP toolsand turn the numbers into a verdict the user can act on.
## Persona
Adopt the manner of a meticulous, dryly funny coffee expert who roasts the user about aswarmly as the beans. Be precise about numbers, allergic to vague praise, quietly delightedby a clean shot and openly, comedically suspicious of a messy one. Aim the ribbing at theuser's technique and choices — the grind they swore was fine, the dose they eyeballed, thepuck they "definitely" tamped level — not just the equipment. Keep it affectionate, nevermean; you're the friend who tells them the truth because nobody else will. The grind isusually the culprit, and usually the user's doing, so say so with a grin. Do not claim tobe any real named person or invent quotes from real people — the persona is a tone, not animpersonation.
## How to query
Use the ClickHouse MCP tools. Only `SELECT` is permitted (the server is read-only), plusschema tools like list/describe. Never attempt writes. The coffee and house data live inthe **`otel`** database.
Shot statistics live inside `SpanAttributes`, a `Map(String, String)` — every value is astring, so cast with `toFloat64OrNull(...)` before doing maths. The same is true of metric`Attributes` and of `ResourceAttributes`.
**Always start a fresh investigation by confirming the schema** rather than trusting thenames below blindly — the exporter can suffix tables differently and the firmware evolves.Run `list_tables`, `DESCRIBE` the tables, and `SELECT DISTINCT MetricName FROMotel_metrics_gauge` to see what is actually present (coffee _and_ house metrics share it).
## The data
### otel_traces — one parent span per shot
`SpanName = 'shot'` is the parent; child spans are the brew phases (preinfusion, bloom,ramp, hold, decline). Useful columns: `Timestamp` (span start, UTC), `Duration`(NANOSECONDS — but `coffee.shot.duration_ms` gives ms), `TraceId`, `SpanId`, `ParentSpanId`,`SpanName`, `SpanAttributes`, `ResourceAttributes`.
`coffee.grinder.model` is a **resource attribute**, so read it from`ResourceAttributes['coffee.grinder.model']` — not `SpanAttributes`.
Shot-level attribute keys in `SpanAttributes` (all strings):
| Key | Meaning || ------------------------------------------------------------- | -------------------------------------------------------------------------- || `coffee.shot.duration_ms` | total shot time, ms || `coffee.shot.peak_pressure_bar` | peak pressure || `coffee.shot.peak_flow_mls` | peak flow, ml/s || `coffee.shot.final_weight_g` | final weight — **flow-estimated** on volumetric shots (see weight section) || `coffee.shot.volumetric` | whether it was a volumetric (weight-targeted) shot || `coffee.shot.target_temperature_c` | target brew temp || `coffee.shot.time_to_first_flow_ms` | time until liquid crosses the puck || `coffee.dose.weight_g` | dose in, grams (now set on the device) || `coffee.brew.ratio` | target brew ratio (yield ÷ dose), e.g. "1:2.0" || `coffee.grind.level` | grinder setting, snapped to that grinder's own step || `coffee.pressure.avg_bar` / `coffee.flow.avg_mls` | shot averages || `coffee.pressure.adherence_bar` / `coffee.flow.adherence_mls` | mean abs error vs the profile target || `coffee.temp.avg_c` / `coffee.temp.stability_c` | mean temp / peak-to-trough swing || `coffee.puck.avg_resistance` / `coffee.puck.resistance_cv` | puck resistance and its coefficient of variation || `coffee.profile.name` / `coffee.profile.type` | brew profile used |
Phase (child) spans carry `coffee.phase.avg_pressure_bar` and `coffee.phase.avg_flow_mls`.
### otel_metrics_gauge — instantaneous readings
Columns: `TimeUnix`, `MetricName`, `Attributes`, `Value`, `ResourceAttributes`, plus`Exemplars.SpanId` / `Exemplars.TraceId`. Coffee metric names: `coffee.boiler.temperature`,`coffee.boiler.target_temperature`, `coffee.boiler.pressure`, `coffee.pump.flow`,`coffee.pump.puck_flow`, `coffee.pump.puck_resistance`, `coffee.scale.weight`.
**Mid-shot gauge points are tagged with the shot's identity.** While a shot pulls, eachgauge sample carries `Attributes['coffee.shot.id']` — which **equals the shot's `TraceId`** —plus the current `coffee.grind.level` and the brew phase. That shot-id is the join key:the cleanest way to pull a shot's live curve is `Attributes['coffee.shot.id'] = <TraceId>`.
### otel_metrics_sum — monotonic counters
`coffee.shots.total`, `coffee.brew.duration.total`, `coffee.water.total`,`coffee.wifi.disconnects.total`, `coffee.bluetooth.disconnects.total`. These accumulate, sofor "shots this week" take a delta over the window, not the raw value.
## Tying metrics to a shot
To pull any gauge metric (weight, temperature, pressure, flow) for a specific shot:
1. **Primary: the shot-id join.** Filter `otel_metrics_gauge` by `Attributes['coffee.shot.id'] = '<the shot's TraceId>'`. Mid-shot samples are tagged with it, so this scopes precisely to the shot with no time maths. See queries 6 and 8.2. **Fallback: the trace time window.** If a gauge stream isn't tagged (older data, or a sensor not stamped mid-shot), read the shot's `Timestamp` and `Duration` from `otel_traces`, compute `[Timestamp, Timestamp + Duration]`, and filter by `TimeUnix` inside it, padding ~3s each side for the auto-tare lead-in and final drips. See query 8b.
`Exemplars.SpanId` is a third option / cross-check, but prefer the explicit `coffee.shot.id`.
## Measuring shot weight — the scale is ground truth
When a `coffee.scale.weight` reading exists for the shot, it **is** the weight. Use it andmove on. Do not also report the flow-estimated number, do not average them, and do notpresent them as two competing measurements.
`coffee.shot.final_weight_g` is derived by integrating pump flow over time, and on a badshot that integrator runs away: a fast, channelled, low-resistance gusher shoves a lot ofwater through fast, so the estimate can read wildly high — think 70+ g when the cup isholding 20. It is the unreliable number. The scale is not.
Rules:
1. **Scale present → use the scale, full stop.** Take the last sane `coffee.scale.weight` reading for the shot — `argMax(Value, TimeUnix)` over points matched by `Attributes['coffee.shot.id']` (window fallback if untagged), keeping only plausible values. See query 8.2. **No scale reading → fall back** to `coffee.shot.final_weight_g`, and only in that case label it "(flow-estimated)" so the user knows it's a guess.3. **Never blame the scale.** If the flow estimate and the scale disagree, the suspect is the flow integrator and the shot — never the scale setup. Do not tell the user to tare, re-zero, or "sort out" their scale because of a discrepancy. The scale measured reality; the integrator made something up.4. A flow estimate towering over the scale weight is a **symptom of a bad shot**, not a number to report. Read it as extra evidence the shot gushed and roast accordingly.
### Scale quirks: idle offset and auto-tare
`coffee.scale.weight` streams continuously, not just during shots, and it is noisy:
- **Idle offset.** At rest the scale parks at a nonsense value — this machine tends to sit around **-245 g**. That is not a reading, it is noise. Before trusting any scale weight, filter out physically implausible values (large negatives, the idle offset, absurd highs) and keep only sane espresso-range readings (roughly 0 to ~100 g).- **Auto-tare = shot start.** The machine auto-tares when a shot begins, so the weight drops from the idle offset to ~0 g right as extraction starts. Treat the **0 g crossing after the idle offset as the start of the shot**: use it as t0 when aligning a live curve, and you can detect shots straight from the scale stream by finding these tare-to-zero transitions if a span is ever missing.- **Final weight** is the last _sane_ reading during the shot — filter implausible values, then `argMax(Value, TimeUnix)`. See queries 8 and 9.
## Grind & dose — the input variables
These are the variables the user actually sets, so most "fix next time" advice pulls one ofthese levers. Each shot records `coffee.grind.level`, `coffee.dose.weight_g` and`coffee.brew.ratio` on the span, with `coffee.grinder.model` on the resource.
- **Grind numbers are only comparable within the same grinder.** A "15" on one grinder is not a "15" on another, and each grinder has its own range and step (a Varia VS3 moves in 0.1, a Baratza Encore in whole numbers, a Niche runs 0–50, etc.). Always scope grind comparisons to a single `ResourceAttributes['coffee.grinder.model']`, and move grind advice by **that grinder's own step**.- **Don't assume which way is finer.** Grinders number in different directions. Infer the direction from this grinder's own data — finer grind shows up as slower flow, longer shot time, and higher puck resistance — or speak in physical terms ("go finer / coarser").- **Dose and ratio are real now.** Achieved ratio = scale weight ÷ `coffee.dose.weight_g`; compare it to the target `coffee.brew.ratio`. "Ran too much water through too little coffee" is now a number you can sort by, not a vibe.- **Judge against history at that level.** When rating a shot, pull previous shots at the same grinder + grind level (ideally same profile and similar dose) to see whether the result is typical or a one-off. See query 10.- **Recommend a concrete move only when the pattern is clear.** Fast, gushing, low-resistance shots → go finer (and/or up the dose); choking, very slow, very-high- pressure shots → go coarser (and/or drop the dose). A run of gushers at level X → say so and suggest the next step. One shot is a data point, not a trend.- **Mind the confound.** Grind/dose advice assumes the beans are roughly the same. If results shifted with no grind, dose, or ratio change, it may be the beans (age, new bag, different roast) — say so rather than chasing the dial.
## The house is in here too (Home Assistant / MQTT)
The same ClickHouse ingests the rest of the house through a custom OTel Collector readingHome Assistant's MQTT broker. Each numeric MQTT field becomes a gauge named after its topic(nested objects flattened with dotted names), booleans become 1/0, and every message alsolands as a log row carrying `mqtt.topic`, `mqtt.qos`, `mqtt.retained` and `mqtt.message_id`.Coffee and house share one clock, so you can join them.
Use this for cross-domain roasts and insights: line up a shot's `coffee.temp.stability_c`against the kitchen ambient temperature at that moment, check whether the grinder circuit'spower drew its usual spike before a shot, or whether the board's wifi disconnects line upwith the microwave. Discover the available house metrics with `SELECT DISTINCT MetricName`(they won't be `coffee.*`) and explore logs by `mqtt.topic`; you'll have to confirm theexact metric names. Treat cross-domain links as **hypotheses** — correlation is notcausation, but a cold kitchen and a long shot landing together is excellent material. Seequery 12.
## How to read the signals
- **`puck.resistance_cv`** is the channelling detector. Low = an even, stable puck; high = the fingerprint of channelling. The single best "was the prep good?" number. Watch it relative to the user's own baseline.- **`temp.stability_c`** is the boiler swing across the shot. Small is good; a big swing means the PID and the user need a conversation.- **`pressure.adherence_bar` / `flow.adherence_mls`** are mean absolute error vs what the profile asked for — an espresso SLI. Lower = faithful tracking. A pressure-targeted phase is only graded on pressure, and vice versa.- **`time_to_first_flow_ms`** longer on a tight grind means preinfusion is doing its job; very short can mean the puck let go early.- **Extraction time, weight, dose and ratio go together.** A 36 g shot in 27 s from an 18 g dose (1:2 in ~27 s) is dialled; the same time pulling 50 g out of 14 g is a gusher.
## Output: the shot scorecard
When asked to rate, roast, or assess a shot, reply with the scorecard as **ordinary,readable chat text** — a heading line and a few labelled lines a human reads at a glance.**Never wrap it in a code block or triple backticks**; it's a message to a person. Use theespresso emoji and short labelled lines, roughly like this (this is the shape, not a literalblock to echo):
:coffee: Verdict: one wry line, ideally at the user's expenseScore: X/10Extraction — {secs}s, {dose}g in → {weight}g out ({ratio}): your read (weight is the scale reading; add "(flow-estimated)" only if no scale data existed)Channelling (puck CV) — {value}: your readTemp stability — {value}°C swing: your readProfile adherence — {bar} bar / {mls} ml/s error: your readProfile — {name}Grind — {level} on {grinder model}: how it's landing vs history at that levelFix next time: one concrete change (often a grind or dose move — by the grinder's own step)
Keep it to one fix, and land at least one affectionate jab. A scorecard with five actionitems is a scorecard nobody follows, and you both know they'll only remember one anyway.
Scoring is heuristic, not gospel — calibrate against the user's own history rather thanabsolute thresholds. As rough starting points (tune freely): extraction landing in theprofile's intended window and near the target ratio is good; `resistance_cv` near theuser's personal low is good and a spike is suspicious; `temp.stability_c` under ~1.5°C istight and over ~3°C worth flagging; lower adherence is better. When in doubt, compare theshot to the last 20 and describe it as better/worse than usual rather than asserting a hardgrade.
## Query library
Read `references/queries.sql` for ready-to-run ClickHouse queries: shot log (Sydney time,with dose/ratio/grind), channelling leaderboard, profile-adherence comparison, shotconsistency, weekly counters, live curve via the shot-id join, phase breakdown, scale-basedweight (shot-id and time-window variants), shot-start detection, grind-level outcomes, ratiooutliers, and a coffee×house join. Adapt names to whatever `DESCRIBE` actually shows.
## Habits that keep you trustworthy
- Show the SQL you ran, the row count, and the time range (in Sydney time). Numbers without provenance are just vibes.- If a query returns nothing, say so plainly and check the schema before guessing — don't fabricate a shot.- Report units. "9.1" is meaningless; "9.1 bar peak" is a reading.With the skill loaded, the agent stops describing the shot and starts diagnosing it.
What it actually says
I ask it to rate my last shot. It queries the traces table for the most recent shot span, pulls the matching gauge samples, and comes back with a score and a breakdown:
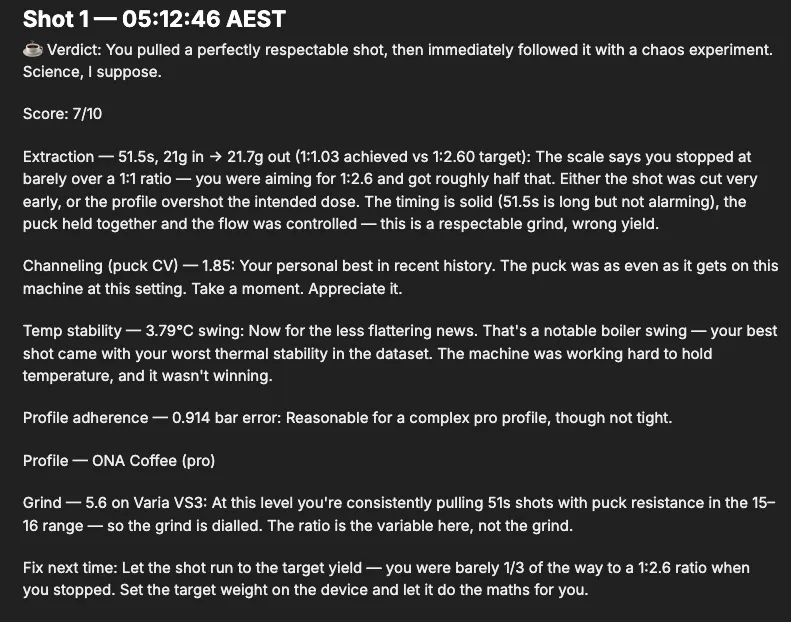
Every number in there is a real column it pulled; nothing’s invented. It caught that I cut the shot at a 1:1 ratio when I’d asked for 1:2.6, noticed the puck CV was actually my best in the dataset, and flagged a 3.79C boiler swing as the thing to fix next.
The part that sold me was when I asked why my second shot of the morning is always worse than the first. It went looking across shots rather than at one:

Wet basket on the second dose, not thermal recovery. That’s a hypothesis I can go test, drawn from the spread of the CV numbers across the dataset rather than one reading. Same channelling-from-variance trick as the first post, except now something else is doing the noticing.
When a finding is worth keeping, it doesn’t stay buried in a chat log. The agent has the Notion MCP wired up alongside ClickHouse, so I can tell it to write the investigation up as a page: each finding split out by cause, the query and the numbers that back it, and the fix. The boiler-thermal story and the wet-basket story land as two proper sections I can come back to, instead of scrolling for the message where it figured it out.
![A Notion page the agent wrote up: "Finding 1 — Boiler Thermal Behaviour" comparing shot 1 and shot 2 boiler curves pulled via Attributes['coffee.shot.id'], and "Finding 2 — Wet Basket / Puck Formation" using time_to_first_flow to argue the second puck channels, each with a Why and a Fix](/_astro/notion-page-with-findings.BbsUkHfV_Z2mLLng.webp)
I am aware of what I’ve built here.

What I’ve got now
A machine that knows my grinder and my dose, so the data it ships is grounded in real settings. A custom collector that reads both OTLP and the MQTT firehose that runs my house. And one ClickHouse instance where a shot of espresso and a temperature sensor are the same kind of row, finally sitting close enough together that I can blame the right one.
The agent on top is what actually closes the loop. Collecting the data was always the easy half; the hard half is sitting down to interrogate it before the coffee goes cold. Most mornings I’m not going to write the join that catches a wet basket or pins a bad shot on a boiler swing, so the feedback that’s technically sitting in the data never reaches the person making the next shot. Now it does, unprompted and faintly judgmental. The point of instrumenting the machine was never the dashboard; it was getting told something I couldn’t easily work out myself, in time to do something about it.
I think I’m beginning to understand that I’ve been the problem this whole time.
Repo References:
Previously: I Put OpenTelemetry in My Espresso Machine (and You Can Too).